
Thách Thức Tài Chính Trong Phát Triển ngôn ngữ lớnvà Giải Pháp Dự Đoán Hiệu Suất.
Khi các nhà nghiên cứu xây dựng các mô hình ngôn ngữ lớn , họ hướng đến mục tiêu tối đa hóa hiệu suất trong phạm vi ngân sách tính toán và tài chính cụ thể. Vì việc huấn luyện một mô hình có thể tốn hàng triệu đô la, các nhà phát triển cần phải thận trọng với những quyết định ảnh hưởng đến chi phí, chẳng hạn như kiến trúc mô hình, bộ tối ưu hóa và tập dữ liệu huấn luyện trước khi cam kết với một mô hình.
Để dự đoán chất lượng và độ chính xác của các dự báo của mô hình lớn, các chuyên gia thường sử dụng luật mở rộng: sử dụng các mô hình nhỏ hơn, rẻ hơn để cố gắng ước tính hiệu suất của một mô hình mục tiêu lớn hơn nhiều. Tuy nhiên, thách thức là có hàng nghìn cách để tạo ra một luật mở rộng.
Nghiên Cứu Đột Phá Từ MIT
Nghiên cứu mới từ các nhà nghiên cứu MIT và MIT-IBM Watson AI Lab đã giải quyết vấn đề này bằng cách thu thập và phát hành một bộ sưu tập hàng trăm mô hình và chỉ số liên quan đến huấn luyện và hiệu suất để ước tính hơn một nghìn luật mở rộng. Từ đó, nhóm nghiên cứu đã phát triển một meta-phân tích và hướng dẫn về cách lựa chọn các mô hình nhỏ và ước tính luật mở rộng cho các họ mô hình ngôn ngữ lớnkhác nhau, để ngân sách được áp dụng tối ưu nhằm tạo ra những dự đoán hiệu suất đáng tin cậy.
Quan Điểm Của Chuyên Gia
"Ý tưởng rằng bạn có thể muốn cố gắng xây dựng các mô hình toán học của quá trình huấn luyện đã có từ vài năm trước, nhưng tôi nghĩ điều mới ở đây là hầu hết công việc mà mọi người đã làm trước đây đều nói rằng, 'chúng ta có thể nói điều gì đó hậu nghiệm về những gì đã xảy ra khi chúng ta huấn luyện tất cả các mô hình này, để khi chúng ta cố gắng tìm ra cách huấn luyện một mô hình quy mô lớn mới, chúng ta có thể đưa ra những quyết định tốt nhất về cách sử dụng ngân sách tính toán của mình?'" - Jacob Andreas, phó giáo sư tại Khoa Kỹ thuật Điện và Khoa học Máy tính và nghiên cứu viên chính tại MIT-IBM Watson AI Lab.
Nghiên cứu này đã được trình bày gần đây tại Hội nghị Quốc tế về Học Máy (ICML 2025) bởi Andreas, cùng với các nhà nghiên cứu MIT-IBM Watson AI Lab là Leshem Choshen và Yang Zhang từ IBM Research.
Ngoại Suy Hiệu Suất - Thách Thức Tài Chính Trong Phát Triển ngôn ngữ lớn
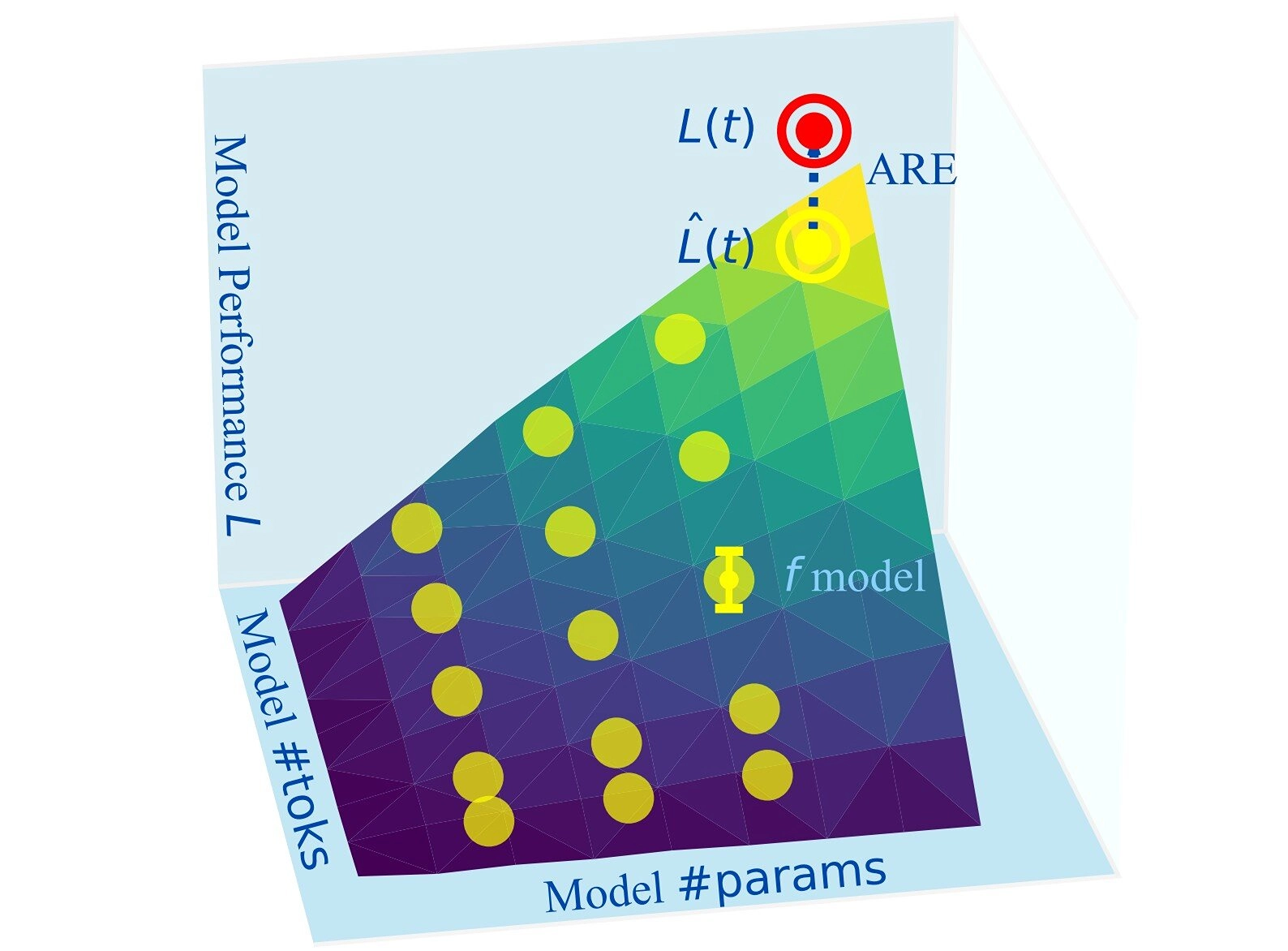
Dù nhìn từ góc độ nào, việc phát triển các mô hình ngôn ngữ lớn đều là một nỗ lực tốn kém: từ việc đưa ra quyết định về số lượng tham số và token, lựa chọn và kích thước dữ liệu, kỹ thuật huấn luyện đến việc xác định độ chính xác đầu ra và điều chỉnh cho các ứng dụng và nhiệm vụ mục tiêu. Luật mở rộng cung cấp một cách để dự báo hành vi mô hình bằng cách liên hệ loss của mô hình lớn với hiệu suất của các mô hình nhỏ hơn, ít tốn kém hơn từ cùng một họ, tránh việc phải huấn luyện đầy đủ mọi ứng viên.
Nguyên Lý Cơ Bản Của Luật Mở Rộng
Chủ yếu, sự khác biệt giữa các mô hình nhỏ hơn là số lượng tham số và kích thước huấn luyện token. Theo Choshen, việc làm rõ luật mở rộng không chỉ cho phép đưa ra quyết định pre-training tốt hơn mà còn dân chủ hóa lĩnh vực này bằng cách cho phép các nhà nghiên cứu không có nguồn lực lớn hiểu và xây dựng luật mở rộng hiệu quả.
Dạng hàm của luật mở rộng tương đối đơn giản, kết hợp các thành phần từ các mô hình nhỏ để nắm bắt số lượng tham số và hiệu ứng mở rộng của chúng, số lượng token huấn luyện và hiệu ứng mở rộng của chúng, cũng như hiệu suất baseline cho họ mô hình quan tâm. Cùng nhau, chúng giúp các nhà nghiên cứu ước tính loss hiệu suất của mô hình lớn mục tiêu; loss càng nhỏ, đầu ra của mô hình mục tiêu càng có khả năng tốt hơn.
Ứng Dụng Thực Tiễn Của Luật Mở Rộng
Những luật này cho phép các nhóm nghiên cứu cân nhắc sự đánh đổi một cách hiệu quả và kiểm tra cách phân bổ tài nguyên hạn chế tốt nhất. Chúng đặc biệt hữu ích cho việc đánh giá mở rộng của một biến số nhất định, như số lượng token, và cho việc A/B testing các thiết lập pre-training khác nhau.
Nói chung, luật mở rộng không phải là mới; tuy nhiên, trong lĩnh vực AI, chúng xuất hiện khi các mô hình phát triển và chi phí tăng vọt. "Giống như luật mở rộng chỉ xuất hiện tại một thời điểm nào đó trong lĩnh vực này," Choshen nói. "Chúng bắt đầu nhận được sự chú ý, nhưng không ai thực sự kiểm tra chúng tốt đến mức nào và bạn cần làm gì để tạo ra một luật mở rộng tốt." Hơn nữa, bản thân luật mở rộng cũng là một hộp đen, theo một nghĩa nào đó.
Xây Dựng Tốt Hơn - Nghiên Cứu Toàn Diện
Để điều tra điều này, Choshen, Andreas và Zhang đã tạo ra một tập dữ liệu lớn. Họ thu thập các ngôn ngữ lớn từ 40 họ mô hình, bao gồm Pythia, OPT, OLMO, LLaMA, Bloom, T5-Pile, ModuleFormer mixture-of-experts, GPT và các họ khác. Những mô hình này bao gồm 485 mô hình độc nhất đã được pre-train, và khi có sẵn, dữ liệu về các checkpoint huấn luyện, chi phí tính toán (FLOPs), epoch huấn luyện và seed, cùng với 1,9 triệu chỉ số hiệu suất về loss và các nhiệm vụ downstream. Các mô hình khác nhau về kiến trúc, trọng số, v.v.
Sử dụng các mô hình này, các nhà nghiên cứu đã khớp hơn 1.000 luật mở rộng và so sánh độ chính xác của chúng trên nhiều kiến trúc khác nhau, kích thước mô hình và phương pháp huấn luyện. Họ cũng kiểm tra xem số lượng mô hình, việc đưa vào các checkpoint huấn luyện trung gian và quá trình huấn luyện một phần ảnh hưởng như thế nào đến khả năng dự đoán của luật mở rộng đối với các mô hình đích.
Nhóm nghiên cứu sử dụng phép đo sai số tương đối tuyệt đối (ARE) - đây là mức chênh lệch giữa dự đoán của luật mở rộng và loss thực tế quan sát được từ một mô hình lớn đã được huấn luyện. Dựa trên phép đo này, họ đã so sánh các luật mở rộng khác nhau. Sau khi phân tích, nhóm đã đưa ra những khuyến nghị thực tiễn cho các chuyên gia AI về yếu tố nào tạo nên một luật mở rộng hiệu quả.
Hướng Dẫn Thực Tiễn Từ Nghiên Cứu
Các hướng dẫn được chia sẻ của họ hướng dẫn nhà phát triển qua các bước và tùy chọn cần xem xét và kỳ vọng:
1. Quyết Định Ngân Sách và Mục Tiêu:
- Quan trọng là phải quyết định ngân sách tính toán và độ chính xác mô hình mục tiêu
- Nhóm nghiên cứu phát hiện rằng 4% ARE là độ chính xác tốt nhất có thể đạt được do nhiễu seed ngẫu nhiên
- Lên đến 20% ARE vẫn hữu ích cho việc ra quyết định
2. Các Yếu Tố Cải Thiện Dự Đoán:
- Bao gồm các checkpoint huấn luyện trung gian thay vì chỉ dựa vào loss cuối cùng
- Loại bỏ dữ liệu huấn luyện rất sớm trước 10 tỷ token vì có nhiễu và giảm độ chính xác
- Ưu tiên huấn luyện nhiều mô hình hơn trải rộng trên nhiều kích thước để cải thiện độ mạnh mẽ
3. Chiến Lược Tối Ưu Hóa Chi Phí:
- Lựa chọn năm mô hình cung cấp điểm khởi đầu vững chắc
- Chi phí có thể được tiết kiệm bằng cách huấn luyện một phần mô hình mục tiêu đến khoảng 30% tập dữ liệu
- Với ngân sách hạn chế: huấn luyện một mô hình nhỏ hơn và mượn tham số từ họ mô hình tương tự.
Những Phát Hiện Bất Ngờ
Một số bất ngờ đã xuất hiện trong công việc này:
1. Mô Hình Nhỏ Huấn Luyện Một Phần Vẫn Có Tính Dự Đoán Cao:
"Về cơ bản, bạn không phải trả gì trong việc huấn luyện, vì bạn đã huấn luyện mô hình đầy đủ rồi, vì vậy mô hình được huấn luyện một nửa, chẳng hạn, chỉ là sản phẩm phụ của những gì bạn đã làm," Choshen nói.
2. Các Giai Đoạn Huấn Luyện Trung Gian Có Thể Tái Sử Dụng:
Các giai đoạn huấn luyện trung gian từ một mô hình được huấn luyện đầy đủ có thể được sử dụng (như thể chúng là các mô hình riêng lẻ) để dự đoán một mô hình mục tiêu khác.
3. Luật Mở Rộng Ngược:
Bất ngờ, các nhà nghiên cứu phát hiện rằng có thể sử dụng luật mở rộng trên các mô hình lớn để dự đoán hiệu suất xuống các mô hình nhỏ hơn.
Phản Bác Quan Điểm Truyền Thống
Nghiên cứu khác trong lĩnh vực này đã đưa ra giả thuyết rằng các mô hình nhỏ hơn là "một loài khác" so với các mô hình lớn; tuy nhiên, Choshen không đồng ý. "Nếu chúng hoàn toàn khác nhau, chúng nên thể hiện hành vi hoàn toàn khác nhau, và chúng không như vậy."
Trong khi công việc này tập trung vào thời gian huấn luyện mô hình, các nhà nghiên cứu dự định mở rộng phân tích của họ sang suy luận mô hình. Andreas nói rằng không phải là "Mô hình của tôi trở nên tốt hơn như thế nào khi tôi thêm nhiều dữ liệu huấn luyện hoặc nhiều tham số hơn, mà thay vào đó là khi tôi để nó suy nghĩ lâu hơn, rút ra nhiều mẫu hơn."
Ông nói rằng lý thuyết về luật mở rộng thời gian suy luận có thể trở nên quan trọng hơn nữa vì "không phải là tôi sẽ huấn luyện một mô hình và sau đó xong. Thay vào đó, mỗi khi người dùng đến với tôi, họ sẽ có một truy vấn mới, và tôi cần tìm ra mô hình của tôi cần suy nghĩ khó khăn đến mức nào để đưa ra câu trả lời tốt nhất. Vì vậy, việc có thể xây dựng những loại mô hình dự đoán như chúng tôi đang làm trong bài báo này thậm chí còn quan trọng hơn."






